Traffic balancing
Sub cluster level load balance
Overview
-
Usually one cluster has more than one sub clusters. In BFE, it is supported to define weights for distributing traffic to each sub cluster.
-
Also there is a special virtual sub cluster "BLACKHOLE" for each cluster.
- Traffic allocated to "BLACKHOLE" will be discarded.
- "BLACKHOLE" is used to prevent traffic overloading to the whole cluster.
-
Load balance between sub clusters, it is a very important feature for BFE. This feature is very useful in multi-IDCs scenario.
Example
-
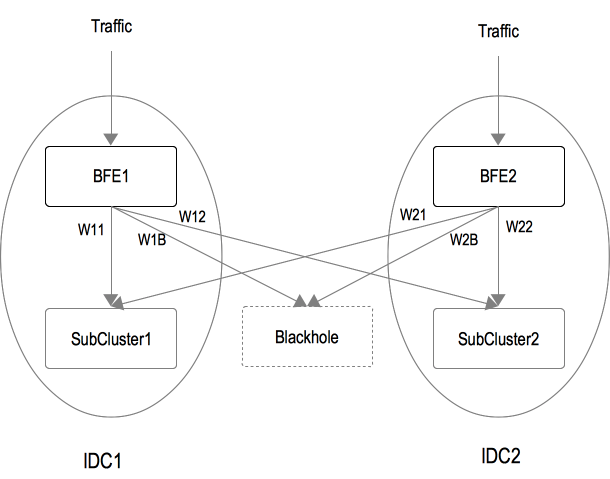
Consider the following scenario:
- Two IDCs:IDC_1, IDC_2
- Two BFE clusters:BFE_1, BFE_2
- Two backend sub clusters:SubCluster_1, SubCluster_2
-
In BFE clusters, weights for distributing traffic to each sub cluster can be configured as follows:
- BFE_1:{SubCluster_1: W11,SubCluster_2: W12, Blackhole: W1B}
- BFE_2:{SubCluster_1: W21,SubCluster_2: W22, Blackhole: W2B}
-
Based on the above configuration, BFE clusters distribute traffic to backend sub clusters.
- For example,if configuration of BFE_1 is {W11,W12, W1B} ={45,45,10}, traffic percentage to SubCluster_1, SubCluster_2 and Blackhole is 45%, 45% and 10%.
Instance level load balance
- Usually, a sub cluster is composed of multiple instances.
- Within sub cluster, several policies is provided for distributing traffic among instances. e.g.,
- WRR(Weighted Round Robin)
- WLC(Weighted Least Connection)
- Instances can be assigned with different weights based on their capacity。
Health check
BFE supports health check for each backend instance.
BFE maintains a state machine for each instance, with two states:
- NORMAL:the instance acts normally in processing request.
- CHECKING:the instance fails to process request and response to BFE. BFE starts health check for this instance, until it acts normally again.
The condition for switching between states:
-
NORMAL to CHECKING, when:
- Number of consecutive failures, in connecting or sending request to the instance, exceeds a threshhod.
-
CHECKING to NORMAL, when:
- BFE receives correct response for health check request from the instance.
Automatic retries
If request forwarding fails, BFE supports retry in two ways:
- In-Sub-Cluster Retry: Re-forward request within the same sub cluster.
- Cross-Sub-Cluster Rery: Re-forward request to other sub cluster.
Connection pool
Two ways are supported for TCP connection between BFE and backend instance:
-
Short-Lived Connection:BFE forwards each request to backend instance with a new established TCP connection.
-
Connection Pool:
-
BFE maintains a connection pool for each backend instance.
-
For a request forwarded to given backend instance:
- If there is an available idle connection in the connection pool, take it from the pool and reuse it.
- Otherwise, establish a new TCP connection.
-
After processing for a request is finished, for the connection used for this request:
- If number of idle connections in the pool is less than configured capacity, the connection is added into the pool.
- Otherwise, close the connection directly.
-
Session stickiness
BFE supports session stickiness.
Session could be defined based on following infos of the request:
- Source IP
- Field in request header, cookie etc.
Session stickiness is supported for the following two levels:
- Sub cluster level: requests of the same session are forwarded to the same sub cluster (may be different instances in this sub cluster).
- Instance level: requests of the same session are forwarded to the same instance.